Projects at Spatial Computing Lab
Here, we introduce the various projects we are currently working on. Each project page provides detailed information, including the project's funding sources, the PhD students involved, start dates, progress updates, related publications, and additional insights. Explore each project to learn more about our ongoing research and its impact.
Trajectory Simulation and Generation
We are seeking PhD students and postdocs to join his fully-funded research collaboration with several universities.
Trajectory Simulation
This research focuses on trajectory simulation, a field dealing with sequences of (ObjectID, Location, Time) triples. Due to privacy concerns, real-world trajectory datasets are scarce, limiting research advancements. To overcome this, this work under DARPA's Ground Truth Program involves simulating urban regions with thousands of agents to generate massive synthetic datasets that mimic real-life patterns. These datasets, free of privacy issues, allow for extensive data mining, such as outlier detection and clustering. Current research directions include scaling simulations to millions of agents and advancing big trajectory data mining using both traditional algorithms and deep learning.
More Information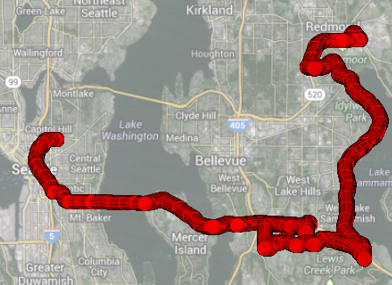
Uncertain Spatial Data Mining
Uncertain Spatial Data Mining
The research focuses on uncertain spatial data mining, particularly on the challenges associated with mining sparse and uncertain trajectory data—sequences of (ObjectID, Location, Time) triples. Due to issues like discrete location captures, infrequent updates, sensor inaccuracies, and privacy considerations, uncertainty is inherent in many datasets. The work explores models to handle this uncertainty, including discrete and continuous models that define possible worlds of data. It includes mining frequent itemsets, clustering, and nearest neighbor searches in uncertain data. Future research is suggested to focus on uncertain clustering and outlier detection, enhancing results with p-values to determine their reliability.
More Information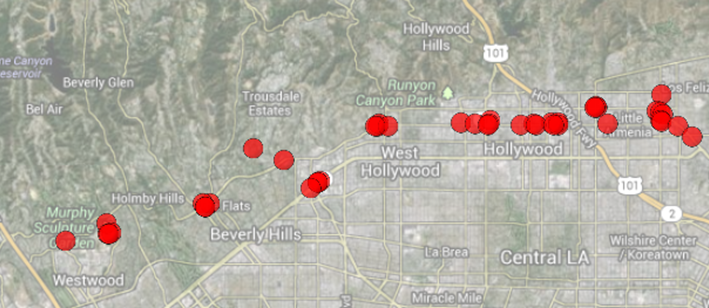
Phylogenetic Data Mining
Phylogenetic Data Mining
The research focuses on phylogenetic data mining to understand the spread of infectious diseases using genetic, spatial, and temporal data. With millions of genome sequences available for diseases like COVID-19, phylogenetic trees can be constructed to trace genetic relationships and infer the origins and spread of cases. The visual analytics tool, PhyloView, enables users to explore these relationships and map case origins, which can help in pandemic prevention efforts. Key challenges include imputing missing data due to the sparsity of sequenced cases and modeling disease spread using advanced methods like spatiotemporal graph convolutional neural networks. The project is funded by an NSF grant and involves collaboration with George Mason University's Department of Geography and Geoinformation Science.
More Information
Reverse Nearest Neighbor Query Processing
Reverse Nearest Neighbor Query Processing
The research focuses on Reverse k-Nearest Neighbor (RkNN) query processing, an important yet non-trivial task in data mining that finds all points having a query point among their k-nearest neighbors. Unlike the symmetric k-Nearest Neighbor (kNN) query, RkNN requires more complex processing due to the asymmetrical nature of the nearest neighbor relationship. Efficient RkNN query processing is crucial for dynamic data mining tasks like updating clusters in DBSCAN when new points are added. The research explores efficient RkNN processing using spatial index structures and other methods, and potential directions include a survey paper on existing methods and exploring learned indexes for RkNN processing. The project is self-funded and involves collaboration with researchers at Monash University, Australia.
More Information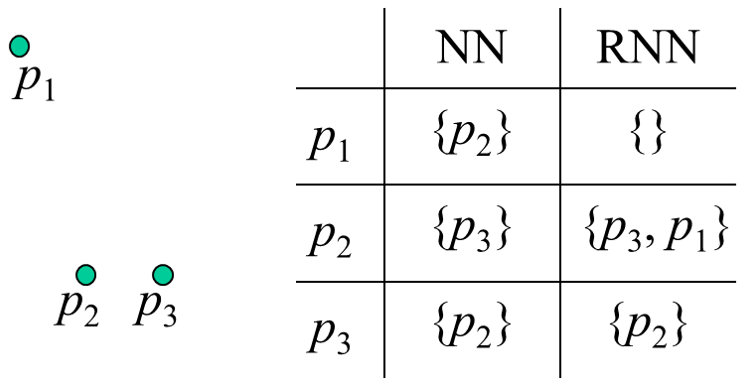
Spatial Clustering
Spatial Clustering
The research explores optimizing the DBSCAN algorithm, a widely used density-based spatial clustering method, by addressing its superlinear runtime complexity. DBSCAN typically requires O(n²) time without index support or O(n log n) with indexing, which can be computationally expensive for large datasets. The proposed solution is a result-sensitive variant that focuses on objects that belong to clusters, leveraging the Maximum Range Sum (MaxRS) Problem to iteratively identify the densest regions in a dataspace. This approach could potentially reduce runtime to O(K * n log n), where K is the number of points in clusters, making it significantly more efficient when K is much smaller than n. Further exploration includes using approximate MaxRS algorithms to achieve an approximate solution for DBSCAN in O(K * n log² n). The project is currently unfunded but open to collaboration with motivated PhD students.
More Information